Lokalne AI na sterydach? AnythingLLM z Nvidia NIM przyspiesza na GeForce RTX
Duże modele językowe (LLM), trenowane na gigantycznych zbiorach danych zawierających miliardy tokenów, zrewolucjonizowały sposób, w jaki tworzymy i przetwarzamy treści. Stanowią one trzon wielu popularnych aplikacji sztucznej inteligencji, od chatbotów i wirtualnych asystentów po zaawansowane generatory kodu. Dla entuzjastów pragnących korzystać z mocy LLM lokalnie na własnym komputerze, z naciskiem na prywatność, powstała wszechstronna aplikacja desktopowa AnythingLLM. Teraz, dzięki nowemu wsparciu dla mikrousług Nvidia NIM na kartach graficznych Nvidia GeForce RTX i Nvidia RTX Pro, użytkownicy mogą liczyć na jeszcze wyższą wydajność i bardziej responsywne lokalne przepływy pracy AI.


Czym jest AnythingLLM?
AnythingLLM to kompleksowa aplikacja AI, która umożliwia użytkownikom uruchamianie lokalnych modeli LLM, implementację systemów RAG (Retrieval-Augmented Generation – generowanie wspomagane wyszukiwaniem) oraz korzystanie z narzędzi agentowych. Działa jako swoisty pomost między preferowanymi przez użytkownika modelami LLM a jego danymi, takimi jak pliki PDF, dokumenty Word, bazy kodu i inne. Aplikacja oferuje dostęp do specjalnych "umiejętności" (ang. skills), które ułatwiają i usprawniają wykorzystanie LLM do konkretnych zadań, takich jak:
- odpowiadanie na pytania: uzyskiwanie odpowiedzi od czołowych LLM – na przykład Llama czy DeepSeek R1 – bez ponoszenia kosztów związanych z usługami chmurowymi,
- zapytania do danych osobistych: wykorzystanie RAG do prywatnego przeszukiwania własnych treści,
- podsumowywanie dokumentów: generowanie streszczeń obszernych materiałów, na przykład prac naukowych,
- analiza danych: wydobywanie wniosków z danych poprzez ładowanie plików i zadawanie zapytań modelom LLM,
- działania agentowe: dynamiczne wyszukiwanie treści przy użyciu lokalnych lub zdalnych zasobów oraz uruchamianie narzędzi generatywnych i akcji na podstawie poleceń użytkownika.
AnythingLLM może łączyć się z szeroką gamą lokalnych modeli LLM typu open-source, a także z większymi modelami działającymi w chmurze, w tym dostarczanymi przez firmy OpenAI, Microsoft czy Anthropic. Dodatkowo, aplikacja zapewnia dostęp do "umiejętności" rozszerzających jej możliwości agentowe AI poprzez hub społeczności. Dzięki prostej instalacji jednym kliknięciem i możliwości uruchomienia jako samodzielna aplikacja lub rozszerzenie przeglądarki, opakowana w intuicyjny interfejs bez skomplikowanej konfiguracji, AnythingLLM stanowi atrakcyjną opcję dla entuzjastów AI, zwłaszcza tych posiadających systemy wyposażone w karty GeForce RTX lub GeForce RTX Pro.



Moc RTX napędza akcelerację w AnythingLLM
Karty graficzne GeForce RTX i NVIDIA RTX PRO oferują znaczący wzrost wydajności podczas uruchamiania modeli LLM i agentów w AnythingLLM. Przyspieszają one proces inferencji dzięki wykorzystaniu rdzeni Tensor, zaprojektowanych specjalnie do akceleracji obliczeń związanych ze sztuczną inteligencją.
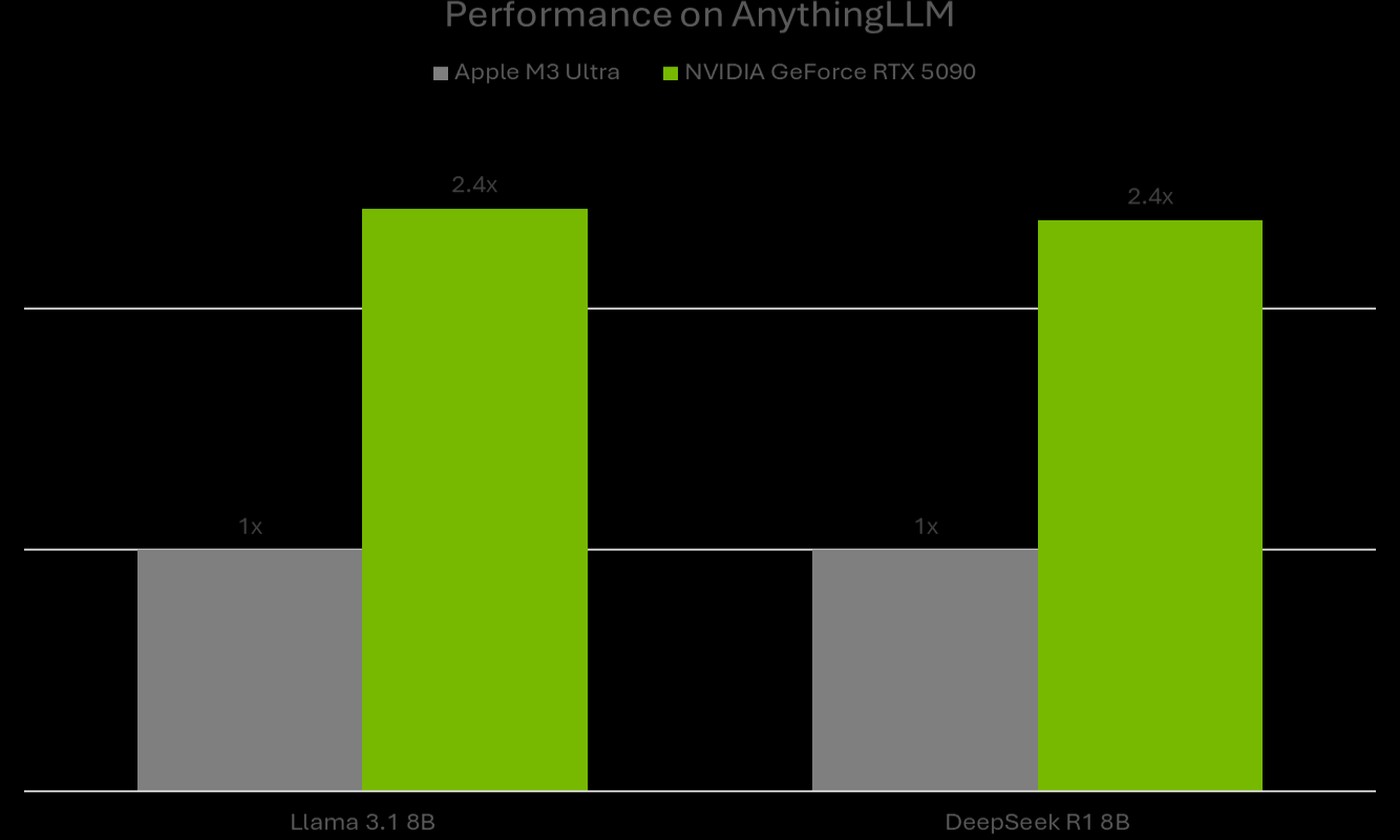
AnythingLLM uruchamia modele LLM za pośrednictwem platformy Ollama, która zapewnia wykonanie na urządzeniu akcelerowane przez biblioteki tensorowe dla uczenia maszynowego, takie jak Llama.cpp i ggml. Zarówno Ollama, jak i wspomniane biblioteki, są zoptymalizowane pod kątem kart GeForce RTX i ich rdzeni Tensor piątej generacji. Według danych firmy Nvidia, wydajność inferencji LLM (testowano modele Llama 3.1 8B oraz DeepSeek R1 8B) w AnythingLLM na karcie GeForce RTX 5090 jest 2,4-krotnie wyższa w porównaniu do układu Apple M3 Ultra.
AnythingLLM teraz ze wsparciem dla Nvidia NIM
Niedawno do AnythingLLM dodano wsparcie dla mikrousług Nvidia NIM. Są to zoptymalizowane pod kątem wydajności, wstępnie spakowane modele generatywnej sztucznej inteligencji, które dzięki uproszczonemu API ułatwiają rozpoczęcie pracy z przepływami AI na komputerach PC wyposażonych w karty RTX.
NIMy są szczególnie przydatne dla deweloperów szukających szybkiego sposobu na przetestowanie modelu GenAI w konkretnym przepływie pracy. Zamiast samodzielnie wyszukiwać odpowiedni model, pobierać wszystkie pliki i konfigurować połączenia, otrzymują oni pojedynczy kontener zawierający wszystko, co niezbędne. Co więcej, mikrousługi NIM mogą działać zarówno w chmurze, jak i lokalnie na komputerze PC, co ułatwia prototypowanie lokalne, a następnie wdrażanie w chmurze.
Dzięki zaoferowaniu ich w ramach przyjaznego interfejsu użytkownika AnythingLLM, użytkownicy zyskują szybki sposób na ich testowanie i eksperymentowanie. Następnie mogą oni podłączyć je do swoich przepływów pracy bezpośrednio w AnythingLLM lub, korzystając z dokumentacji Nvidia AI Blueprints i NIM oraz przykładowego kodu, zintegrować je bezpośrednio z własnymi aplikacjami lub projektami.
W miarę jak Nvidia będzie dodawać nowe mikrousługi NIM i referencyjne przepływy pracy – takie jak rosnąca biblioteka AI Blueprints – narzędzia pokroju AnythingLLM odblokują jeszcze więcej multimodalnych zastosowań sztucznej inteligencji. Dla użytkowników ceniących lokalne przetwarzanie danych i prywatność, AnythingLLM wzmocnione technologiami NVIDIA staje się coraz bardziej kompletnym i wydajnym narzędziem w świecie AI.



